2023.3.7
第2回 数理モデルデザイン研究会 (Society for Math for Design)
科学分野で説明対象の仕組み(デザイン、メカニズム)を明らかにすることは、観察データから具体的な数理モデルを同定することと関係が深い。また、社会の仕組みや、人々の行動の分析の背後には、暗黙のもしくは明示的な「数理モデル」の仮定が想定され、このようなモデルに基づきデザインがなされている。つまり、「数理モデル」は、現代のデザインにおいて重要な因子である。そこで、「数理モデル」を様々な角度から理解する「数理モデルデザイン研究会」を立ち上げます。
第2回では、データの発生源であるモデルを推定することに役立つ「ベイズ推定」を取り上げます。
ベイズ推定を簡単に説明しますと、観測されたデータから、推定したい対象(例えば、データを作り出すメカニズムを表現するパラメータを有するモデル)を、確率的に推論する汎用性の高い手法です。また、ベイズ推定の利点は、ニューラルネットワークに比べて比較少量のデータでも対応可能であること、そして、事前知識や仮説を、生成モデルのパラメータの事前確率という確率分布モデルに反映させることが可能であることです。また、最近は、深層学習とベイズが結びついたベイズ深層学習も着目されており、これはニューラルネットワークの発展の一方向を示しているのかもしれません。
今回は、澤井賢一先生に講師をお願いしており、ベイズ推定のイントロダクションと応用例について述べて頂きます。
是非ご参加ください。
日時
2023年3月27日(月) 18:20~19:30
場所
九州大学大橋キャンパス デザインコモン2F
(対面またはオンラインで参加可能。演者は会場で参加します。)
プログラム
1.澤井賢一「ベイズ推定によるデータの解析と現象のモデル化」(40分)
2.丸山修「GPT(Generative Pre-trained Transformer)系モデルが得意なことと不得意なこと」(5分)
3.質疑応答および議論
進行:丸山修
主催:デザイン基礎学研究センター、未来構想デザインコース
レビュー
当研究会の趣旨は、数理モデルのデザインを中心に位置づけ、「デザインのための数理モデル」と「現象理解のための数理モデルのデザイン」という座標軸を意識しつつ、研究と教育の視点から幅広く議論するサロン的な場を作ることにあります。
2023年3月27日月曜日に第2回の数理モデルデザイン研究会を次のプログラムで開催しましたのでここに報告します。
プログラム
1.澤井賢一先生「ベイズ推定によるデータの解析と現象のモデル化」
2.丸山 GPT(Generative Pre-trained Transformer)系モデルが得意なことと不得意なこと
3.質疑応答および議論
今回は、対面4名(デザインコモン・アクティブラーニングスペース)とオンライン5名の方々に参加して頂きました。
澤井先生のお話は次のような内容でした。まず、「ベイズの定理」 P(X|Y) = P(Y|X)P(X)/P(Y) の成り立ちを説明して頂きました。次に、現象に対して確率変数XとYがそれぞれ原因と結果を表す変数とすると、ベイズの定理の意味するところは「結果が所与のもとで原因が発生する(事後)確率 P(原因|結果)は、原因が所与のもとで結果が発生する確率(正確には尤度) P(結果|原因)と原因の事前確率 P(原因) の積に比例する」というものでした。つまり、観測データからこれらを生成するモデルの特性が確率的に推定できるということでした。

次に、この定理を活用したベイズ推定の具体例として、「ベイズ推定による知覚システムのモデル化」と「音楽聴取時の快情動に関するベイズ理論」について解説して頂きました。
「ベイズ推定による知覚システムのモデル化」に関しては、次の内容でした。脳は、感覚器を通してしか外界を知りえない。感覚器の情報は、大脳に届くまでの神経情報伝達によりとても多くのノイズが含まれる。つまり、人の脳は外界で生じた真の情報を直接知ることはできず、感覚器が観測したノイズを含んだ情報しか得られない。そこで、X, Yをそれぞれ「外界の様子」、「感覚器を通して得た情報」を表す変数とすることにより、「感覚器を通して得た情報」が与えられたもとで「外界の様子」を表す(事後)確率分布について詳しく解説して頂きました。
また、「音楽聴取時の快情動に関するベイズ理論」に関しては、文献D. Temperley , “A Bayesian Theory of Musical Pleasure,” Society for Music Perception and Cognition 2011
から、事後分布P(調性|音符列)のエントロピーを見ることで、聴取者の理解度の時系列をモデル化し、「構造の理解が進んだときに、聴取者は快を感じる」というTemperley の主張について紹介して頂きました。
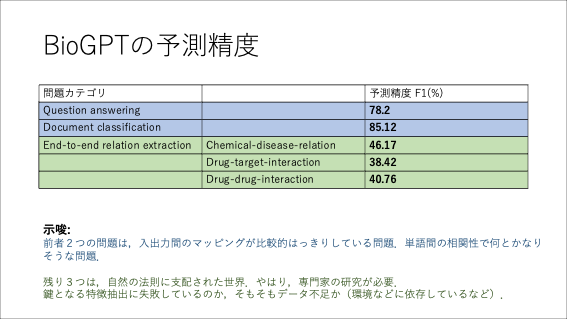
丸山の方からは、1500万のPubMed論文のタイトルとアブストラクトからpre-trainしたGPT系のモデルBioGPT [Luo, et al. 2022]で示されている予測実験の興味深い結果を報告しました。具体的には、下の表に示されているように自然言語処理的なQuestion answering と Document classification という問題に対しては、80%程度の高い予測率を達成しています。一方、chemical-disease, drug-target, drug-drug の物質間相互作用の有無の予測問題はかなり解けない、つまり専門家が地道に研究するしかないという示唆が得られています。
以上です。